
There are times when you want to access processes running on your host machine e.g. databases etc. from your minikube Kubernetes cluster in Virtual Box (or any other supported provider)
For details, continue reading this blog on Medium
Cheers!
There are times when you want to access processes running on your host machine e.g. databases etc. from your minikube Kubernetes cluster in Virtual Box (or any other supported provider)
Cheers!
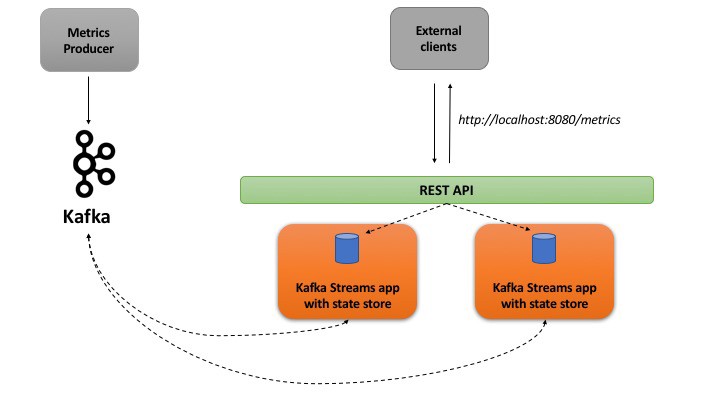
This blog post explores the Interactive Queries feature in Kafka Streams with help of a practical example. It covers the DSL API and how the state store information was exposed via a REST service
Everything is setup using Docker including Kafka, Zookeeper, the stream processing services as well as the producer app
Here is a bird’s eye view of the overall solution looks
Cheers!
Although its rare, but there are times when you actually want to see errors in your code – more importantly, at the right time !
You need to be mindful of this while using the Kafka Go client producer. For e.g. if you were to supply an incorrect value for the Kafka broker …
… assuming you don’t have a Kafka broker at foo:9092, you would expect that the above code will respond with producer creation failed along with the specific error details. Instead, the flow carries on and ends by printing done. This is because the error returned by Produce is only in case message does not get enqueued to the internal librdkafka queue
Hook up to the delivery producer reports channel (using Producer.Events()) in order to catch this error – better late than never right !
Now, the error is rightfully returned – producer error foo:9092/bootstrap: Failed to resolve 'foo:9092': nodename nor servname provided, or not known (after 1543569582778ms in state INIT)
You can also provide your own channel to the Produce method to receive delivery events. Only the error is handled and the other possible event i.e. *kafka.Message is ignored under the default case umbrella
Cheers!
sdfsdfsdfsdfsdf
Here is a Docker based example for Kafka using Go client
Events (custom channel is another option or you can choose not to get notified)Events) channel – Poll()ing is another alternativeCheck out the README – it’s super easy to get going, thanks to Docker Compose!
Cheers!
With Redis 5 (in RC state at time of writing), cluster creation utility is now available as part of redis-cli which is easier as compared to the (previous) ruby way of doing it (using redis-trib)
check out the release notes for more info
Here is the command list – docker run -i --rm redis:5.0-rc redis-cli --cluster help
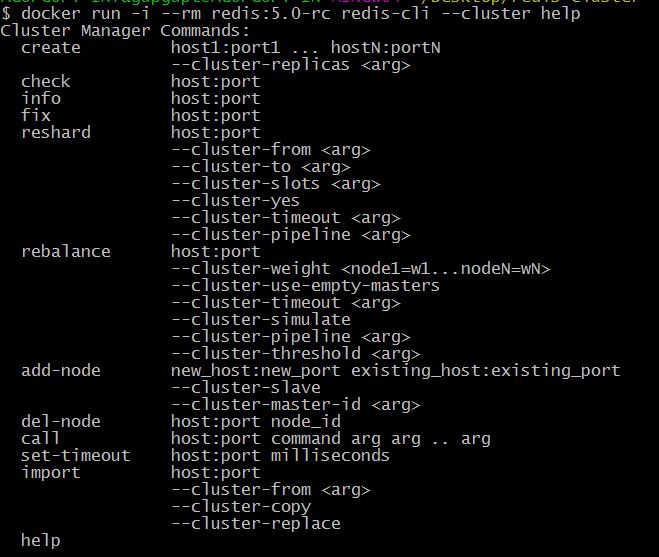
redis-cli –cluster help
It’s super simple to create a 6-node Redis Cluster (3 masters and corresponding slaves) on Docker
| #———— bootstrap the cluster nodes ——————– | |
| start_cmd='redis-server –port 6379 –cluster-enabled yes –cluster-config-file nodes.conf –cluster-node-timeout 5000 –appendonly yes' | |
| redis_image='redis:5.0-rc' | |
| network_name='redis_cluster_net' | |
| docker network create $network_name | |
| echo $network_name " created" | |
| #———- create the cluster ———————— | |
| for port in `seq 6379 6384`; do \ | |
| docker run -d –name "redis-"$port -p $port:6379 –net $network_name $redis_image $start_cmd; | |
| echo "created redis cluster node redis-"$port | |
| done | |
| cluster_hosts='' | |
| for port in `seq 6379 6384`; do \ | |
| hostip=`docker inspect -f '{{(index .NetworkSettings.Networks "redis_cluster_net").IPAddress}}' "redis-"$port`; | |
| echo "IP for cluster node redis-"$port "is" $hostip | |
| cluster_hosts="$cluster_hosts$hostip:6379 "; | |
| done | |
| echo "cluster hosts "$cluster_hosts | |
| echo "creating cluster…." | |
| echo 'yes' | docker run -i –rm –net $network_name $redis_image redis-cli –cluster create $cluster_hosts –cluster-replicas 1; |
Once executed, you should see a similar output
| redis_cluster_net created | |
| f66517db305c3f270f756f1fbd40611d123fc69c040695147bb43cc153491093 | |
| created redis cluster node redis-6379 | |
| 726672fad3d815e7a07ac892acd7bb412e91193b28527654c483cd5debbfd011 | |
| created redis cluster node redis-6380 | |
| 75d8621153b3cbb7962fcf90a5a35108fe042a05e9a78b920c2655caa5a1f7ec | |
| created redis cluster node redis-6381 | |
| d9df8c47ccaf21470bcbc2b89f485e1cd9f68917019fa6ba7ebbac59b792b41b | |
| created redis cluster node redis-6382 | |
| 21edb22225abc54140e437091ddb19cd452542e3d82e7839470a3bbf6a0ddbf7 | |
| created redis cluster node redis-6383 | |
| 5cdd12537f954aa5df4bd0c173f0670dd126c4c925336c7e9054d147508c12d9 | |
| created redis cluster node redis-6384 | |
| IP for cluster node redis-6379 is 172.27.0.2 | |
| IP for cluster node redis-6380 is 172.27.0.3 | |
| IP for cluster node redis-6381 is 172.27.0.4 | |
| IP for cluster node redis-6382 is 172.27.0.5 | |
| IP for cluster node redis-6383 is 172.27.0.6 | |
| IP for cluster node redis-6384 is 172.27.0.7 | |
| cluster hosts 172.27.0.2:6379 172.27.0.3:6379 172.27.0.4:6379 172.27.0.5:6379 172.27.0.6:6379 172.27.0.7:6379 | |
| creating cluster…. | |
| >>> Performing hash slots allocation on 6 nodes… | |
| Master[0] -> Slots 0 – 5460 | |
| Master[1] -> Slots 5461 – 10922 | |
| Master[2] -> Slots 10923 – 16383 | |
| Adding replica 172.27.0.5:6379 to 172.27.0.2:6379 | |
| Adding replica 172.27.0.6:6379 to 172.27.0.3:6379 | |
| Adding replica 172.27.0.7:6379 to 172.27.0.4:6379 | |
| M: 78da8a4a346c3e43d2a013cfc1f8b17201ecaaf9 172.27.0.2:6379 | |
| slots:[0-5460] (5461 slots) master | |
| M: 43b4c865269d9d57b840ae6d90ef84d74678eee1 172.27.0.3:6379 | |
| slots:[5461-10922] (5462 slots) master | |
| M: 69801d3672c7dbc24fb670601ca088d701ff0902 172.27.0.4:6379 | |
| slots:[10923-16383] (5461 slots) master | |
| S: 9934e5d049ceb6088c756d2faa72b76196d8503a 172.27.0.5:6379 | |
| replicates 78da8a4a346c3e43d2a013cfc1f8b17201ecaaf9 | |
| S: 12cef6f9c1c212a209eaef742c5a7c91aec32c37 172.27.0.6:6379 | |
| replicates 43b4c865269d9d57b840ae6d90ef84d74678eee1 | |
| S: 73eb4b587145bb2ebeae65679591ea11736cd212 172.27.0.7:6379 | |
| replicates 69801d3672c7dbc24fb670601ca088d701ff0902 | |
| Can I set the above configuration? (type 'yes' to accept): >>> Nodes configuration updated | |
| >>> Assign a different config epoch to each node | |
| >>> Sending CLUSTER MEET messages to join the cluster | |
| Waiting for the cluster to join | |
| … | |
| >>> Performing Cluster Check (using node 172.27.0.2:6379) | |
| M: 78da8a4a346c3e43d2a013cfc1f8b17201ecaaf9 172.27.0.2:6379 | |
| slots:[0-5460] (5461 slots) master | |
| 1 additional replica(s) | |
| M: 69801d3672c7dbc24fb670601ca088d701ff0902 172.27.0.4:6379 | |
| slots:[10923-16383] (5461 slots) master | |
| 1 additional replica(s) | |
| M: 43b4c865269d9d57b840ae6d90ef84d74678eee1 172.27.0.3:6379 | |
| slots:[5461-10922] (5462 slots) master | |
| 1 additional replica(s) | |
| S: 73eb4b587145bb2ebeae65679591ea11736cd212 172.27.0.7:6379 | |
| slots: (0 slots) slave | |
| replicates 69801d3672c7dbc24fb670601ca088d701ff0902 | |
| S: 12cef6f9c1c212a209eaef742c5a7c91aec32c37 172.27.0.6:6379 | |
| slots: (0 slots) slave | |
| replicates 43b4c865269d9d57b840ae6d90ef84d74678eee1 | |
| S: 9934e5d049ceb6088c756d2faa72b76196d8503a 172.27.0.5:6379 | |
| slots: (0 slots) slave | |
| replicates 78da8a4a346c3e43d2a013cfc1f8b17201ecaaf9 | |
| [OK] All nodes agree about slots configuration. | |
| >>> Check for open slots… | |
| >>> Check slots coverage… | |
| [OK] All 16384 slots covered. |
To check cluster, you can run
docker run -i --rm --net redis_cluster_net redis:5.0-rc redis-cli --cluster check localhost:6380docker run -i --rm --net redis_cluster_net redis:5.0-rc redis-cli --cluster info localhost:6380Cheers!
I am happy to announce that the first few chapters of Practical Redis are now available
It is a hands-on, code-driven guide to Redis where each chapter is based on an application (simple to medium complexity) which demonstrates the usage of Redis and its capabilities (data structures, commands etc.).
The applications in the book are based on Java and Golang. The Java based Redis client libraries which have been used in this book include Jedis, Redisson and Lettuce while go-redis is used as the client library for Golang. Docker and Docker Compose are used to deploy the application stack (along with Redis)
Here is a quick outline of the book contents
reliable queues (Redis LISTs), SETs and HASHesThe below chapters are work in progress on and will be made available in subsequent releases of this book
Go check it out & stay tuned for more updates
Cheers!
I stumbled upon geo.lua which seemed to be an interesting library
It’s described as – “… a Lua library containing miscellaneous geospatial helper routines for use with Redis“
Here is an example of using it with the Go Redis client (go-redis). This is what it does in a nutshell
GEOADD) co-ordinates to a Redis Geo setgeo.lua is invoked using EVAL
GEOPATHLEN (a variadic form of GEODIST)To run, refer README – its super simple
Cheers!
Using the Go HTTP client from a alpine docker image will result in this error – x509: failed to load system roots and no roots provided
Solution: alpine is a minimal image, hence CA certificates are required. You add that in the Dockerfile as per below example
FROM alpine RUN apk add --no-cache ca-certificates COPY my-app . etcd is a distributed, highly available key-value store which serves as the persistent back end for Kubernetes

Here is an example to demonstrate its Watch feature. For details, check out the README (and the sample code) on Github
It uses
Summary
Cheers!
In a previous blog, you saw an example of NATS along with producer and consumer – based on Docker Compose. This post uses the same app, but runs on Kubernetes

For how to run, follow the README on Github
High level overview
Service object is created automatically – uses ClusterIP by default
NATS Kubernetes Service object
Serviceis used in the application logic to locate NATS server. Note its usage hereCheers!
![]()


