
Partitions are the key to scalability attributes of Kafka. Developers can also implement custom partitioning algorithm to override the default partition assignment behavior. This post will briefly cover
- Partitions in general
- Data distribution, default partitioning, and
- Example of custom partitioning logic
Partitions in Kafka
In Kafka, partitions serve as another layer of abstraction – a Partition
Here is a quickie
- Topic is divided into one (default, can be increased) or more partitions
- A partition is like a log
- Publishers append data (end of log) and each entry is identified by a unique number called the offset. The data in the partition is immutable
- Records in the partition are immutable and stored for a configurable amount of time (after which they are removed from disk)
- Consumers can read (they pull data) from any position (offset) in a partition, move forward or back
- Each partition is replicated (as per replication factor configuration) which means that it can have (at most) one primary copy (on the leader node) and and 0 or more copies(follower nodes)
- Kafka ensures strict ordering within a partition i.e. consumers will receive it in the order which a producer published the data to begin with
Distributing partitions across nodes
In Kafka, spreading/distributing the data over multiple machines deals with partitions (not individual records). Scenario depicted below
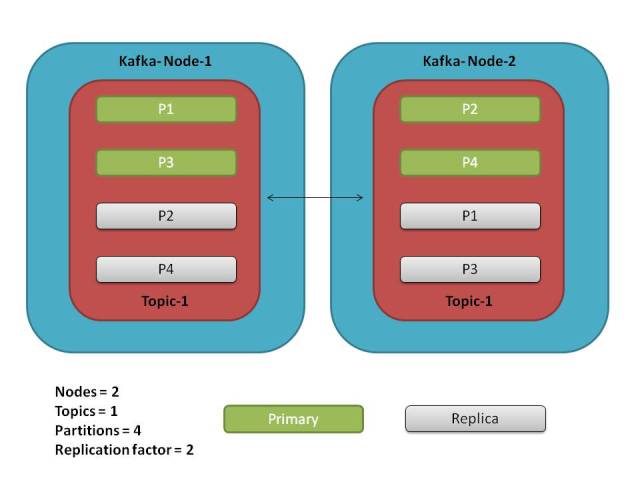
Partition distribution over a Kafka cluster
- Primary partition placement: 2 partitions per node e.g. N1 will have P1,P3 & N2 will have P2, P4
- Replica placement: one replica for each partition since the factor is 2 i.e. one replica in addition to a primary copy (total 2)
Data and Partitions: the relationship
When a producer sends data, it goes to a topic – but that’s 50,000 foot view. You must understand that
- data is actually a key-value pair
- its storage happens at a partition level
A key-value pair in a messaging system like Kafka might sound odd, but the key is used for intelligent and efficient data distribution within a cluster. Depending on the key, Kafka sends the data to a specific partition and ensures that its replicated as well (as per config). Thus, each record
Default behavior
The data for same key goes to same partition since Kafka uses a consistent hashing algorithm to map key to partitions. In case of a null key (yes, that’s possible), the data is randomly placed on any of the partition. If you only have one partition: ALL data goes to that single partition
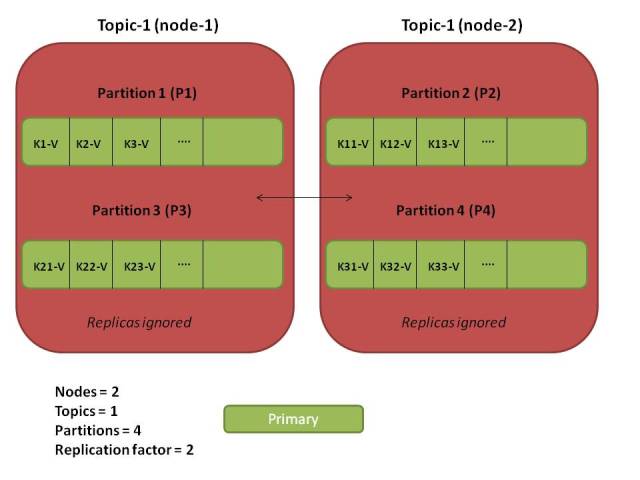
Data in partitions
Custom partitioning scheme
You can plugin a custom algorithm to partition the data
- by implementing the
Partitionerinterface - configure Kafka producer to use it
Here is an example
Generate random partitions which are within the valid partition range
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public class RandomKakfaPartitioner implements Partitioner { | |
| @Override | |
| public int partition(String topic, Object key, byte[] keyBytes, Object val, byte[] valBytes, Cluster cluster) { | |
| int totalParitions = cluster.partitionCountForTopic(topic); | |
| Random intgerGen = new Random(); | |
| int targetPartition = intgerGen.nextInt(totalParitions-1); //partition id starts with 0 | |
| System.out.println("Record will be placed in partition: "+ targetPartition); | |
| return targetPartition; | |
| } | |
| @Override | |
| public void close() { | |
| //no-op | |
| } | |
| @Override | |
| public void configure(Map<String, ?> map) { | |
| //no-op | |
| } | |
| } |
Further reading
- Kafka documentation
- Kafka javadocs
Cheers!



Pingback: Kafka producer and partitions | Simply Distributed
Pingback: 聊聊partition的方式 | 喜乐从心,不应由人
Pingback: 聊聊partition的方式 - 奇奇问答
Pingback: How to Talk about partition – DDCODE